

Nel mondo dell’informatica, si sa, ogni tecnologia o concetto rischia di diventare obsoleto nel giro di pochissimo tempo. Questo perché dovendo migliorare continuamente le prestazioni di un sistema (hardware o software, non fa differenza), si cerca di applicare modelli sempre più evoluti, cercando di alzare ogni volta l’asticella fino al raggiungimento utopico di uguaglianza di ragionamento tra uomo e macchina.
Nell’ultimo quinquennio i trending topics nel mondo dell’Information Technology hanno visto susseguirsi vari argomenti, tra i quali possiamo riportare:
- Informatica quantistica
- Blockchain (grazie anche alla notorietà dei bitcoin che ne fanno uso)
- Big data
- IoT
- Realtà aumentata
- Realtà virtuale
Tutti mirano ad alzare la famosa asticella delle prestazioni, ma tra questi, soprattutto recentemente, è comparso anche il Machine Learning, spesso unito al concetto di intelligenza artificiale. Vediamo più in dettaglio di cosa si tratta.
Machine Learning: una definizione
Il Machine Learning, conosciuto anche come apprendimento automatico e spesso abbreviato con l’acronimo ML, è una branca dell’intelligenza artificiale che si occupa di migliorare le prestazioni di un sistema informatico attraverso l’apprendimento.
Per fare questo il ML crea automaticamente e in autonomia dei modelli, a partire dai dati che vengono utilizzati, per alimentare i metodi e gli algoritmi che compongono il sistema.
Il concetto di ML si può illustrare attraverso un semplice esempio matematico.
Immaginiamo di avere un problema che viene risolto da una qualsiasi funzione f(x); tale problema può essere espresso come segue: y = f(x), dove y è il risultato della funzione f applicata all’argomento x (i dati in input alla funzione).
Perciò avremo una classica:
y = f(x)
Normalmente in un qualsiasi ambito di produzione software, un programmatore scrivendo il proprio codice, non fa altro che specificare la logica che descrive il comportamento della funzione f.
Quindi: si conoscono i dati di input x, si conosce la funzione f, ovvero la logica da applicare ai dati di input e il programma si occupa di determinare il risultato y.
Con il Machine Learning i protagonisti rimangono gli stessi, ma cambia l’output finale, che non sarà più y, ma sarà la funzione f.
Questo perché il ML si occupa proprio, avendo i dati di input e il risultato, di determinare la logica che deve applicare per riprodurre lo stesso funzionamento anche con differenti set di dati e risultati.
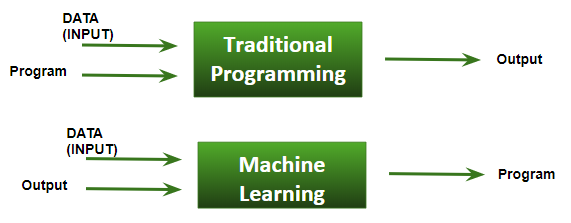
In sintesi, possiamo dire che il compito del ML non è di trovare il risultato di un problema, ma di capire le logiche che portano alla risoluzione di un problema. E questo permette ad un sistema informatico di migliorare continuamente le proprie prestazioni, potendo continuamente apprendere nuovi modi di approcciare sistemi con incognite.
Possiamo vedere il ML come un bambino che sottoposto a continue nuove esperienze, costruisce la propria intelligenza.
Ad esempio, tutti noi sappiamo con assoluta certezza che perdendo un dentino, il topino porterà un soldino. Il bambino lo apprende con l’esperienza, perde il primo dentino da latte e si vede arrivare il soldino il mattino seguente sotto al cuscino. Al secondo dente perso, altro soldino in arrivo, e così via.
Allo stesso modo il ML applica gli stessi concetti. Visto che si occuperà di determinare la relazione tra un dente e i soldi, la funzione f sarà “perdere”. È alquanto curioso come la stessa funzione valga anche quando applicata al mondo dei dentisti. Ma il ML potrebbe accorgersi anche di questa correlazione e costruire sistemi complessi ed evoluti trovando le relazioni tra i dati forniti in input e i risultati monitorati.
Ovviamente la questione non è di semplice risoluzione e per raggiungere questi obiettivi vengono utilizzati algoritmi matematici e statistici di carattere generico che permettono di raggiungere risultati ottimali quando alimentati con una grande serie di dati, che normalmente sarebbero ingestibili se sottoposti all’analisi di un essere umano, in quanto richiederebbero troppo tempo per essere valutati.
Proprio la valutazione è una delle fasi del processo di ML.
Questo, infatti, per funzionare a dovere deve essere sottoposto ad una fase di training degli algoritmi (addestramento), alimentando gli stessi con i dati in nostro possesso. Successivamente subentra la fase di evaluation (valutazione) dei risultati sulla base dell’ottimizzazione dei parametri.
Questo permette di arrivare a definire la procedura e i comportamenti da applicare anche su basi di dati diverse, permettendo di definire anche il valore di confidenza che l’algoritmo ha nel determinare il modello.
Più alta sarà la confidenza, più gli algoritmi applicati saranno stati efficaci nel trovare punti in comune e tendenze simili tra i vari casi analizzati.
Continua con la lettura: Machine Learning: come le macchine apprendono – PARTE 2
