

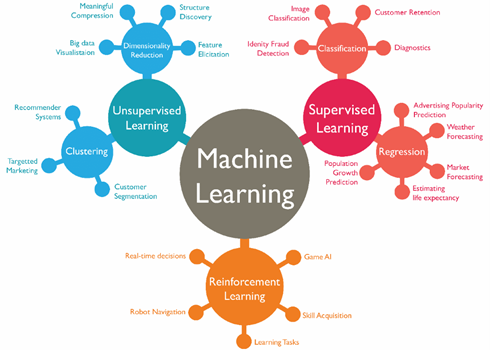
Senza scendere troppo nel dettaglio, possiamo dire che esistono tre classificazioni di algoritmi di machine learning:
- Supervised (supervisionato)
- Unsupervised (non supervisionato)
- Reinforcement (rafforzato)
SUPERVISED LEARNING
Nel caso dei supervisionati, gli algoritmi vengono istruiti con l’ausilio (umano o di sensori o di altri sistemi) di informazioni a corredo dei dati di input. Per esempio, un utente può specificare a mano quali siano i risultati validi da considerare ai fini del miglioramento del modello.
Un esempio classico di questo tipo di algoritmi è la classificazione automatica delle immagini. Supponiamo per esempio di voler riconoscere automaticamente se un’immagine rappresenta la foto di un gatto (ci vorrebbe un algoritmo per capire perché i gatti sono così virali su internet). Solitamente l’algoritmo viene allenato da una persona che dato un insieme di immagini di input iniziali, applica l’etichetta “gatto” a quelle che rappresentano effettivamente dei gatti. A questo punto l’algoritmo di occuperà di riconoscere le analogie tra quelle immagini e cercherà di applicare la stessa logica su altri set di dati in input.
UNSUPERVISED LEARNING
Nel caso di algoritmi non supervisionati invece, non ci sono aiuti esterni, ma è l’algoritmo stesso a doversi occupare di trovare le analogie, le caratteristiche e le ripetizioni sui dati passati in input.
Un esempio è la pubblicità mirata che spesso ritroviamo nei social network. Immaginiamo di cercare nel motore di ricerca un dentifricio (giusto per restare in tema). Probabilmente al primo accesso al nostro social network preferito, troveremo delle inserzioni relative a dentifrici, oppure spazzolini o collutori. Questo perché un algoritmo di machine learning ha analizzato i nostri dati di navigazione e in base alle caratteristiche comuni di tali dati con altri prodotti presenti nel proprio catalogo, ha proposto quelli più compatibili. In questo caso ha proposto tutti prodotti relativi alla categoria “igiene dentale”.
REINFORCEMENT LEARNING
L’ultimo paradigma di apprendimento, ovvero quello rafforzato, punta invece a realizzare degli agenti autonomi che riescano autonomamente a prendere decisioni al fine del raggiungimento di determinati obiettivi preposti, interagendo con l’ambiente in cui si trovano. Per fare questo gli agenti rilevano le caratteristiche dell’ambiente che li circondano attraverso dei sensori e mettono in pratica delle azioni o decisioni attraverso degli attuatori. Ogni volta che l’agente prende una decisione che porta all’obiettivo, ottiene una ricompensa e l’algoritmo sarà impostato per cercare di massimizzare queste ricompense nelle iterazioni future.
Esempio classico dell’applicazione di questi algoritmi, sono i sistemi di guida autonoma dove le automobili attraverso i vari sensori installati sulla vettura, percepiscono le caratteristiche dell’ambiente che li circonda e riescono ad intervenire tramite gli attuatori (sterzo, acceleratore, freno, luci, etc.) per fare in modo che il veicolo raggiunga la destinazione prefissata (obiettivo) senza incidenti e senza mettere a repentaglio la vita delle persone.
Quanto appena appreso è solo una veloce infarinatura di tutti i concetti coperti dal machine learning.
Considerando l’obiettivo finale, ovvero l’emulazione dell’intelligenza umana, si può ben immaginare quanto complicati possano essere alcuni argomenti trattati, che fanno sempre riferimento a modelli matematici complessi e spesso interconnessi tra loro.
RETI NEURALI E DEEP LEARNING
Spesso nell’ambito del ML, si sentono spesso nominare “Reti Neurali” (Neural Networks) e “Deep Learning”.
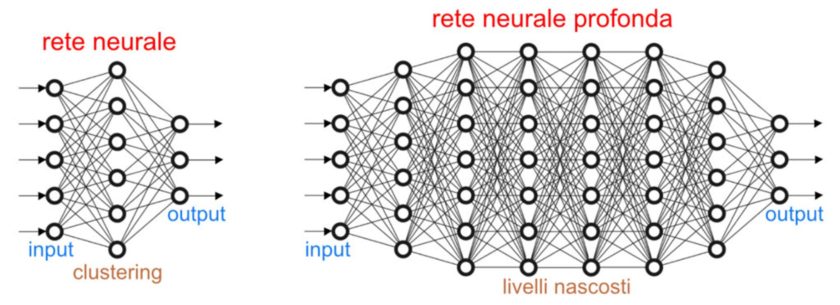
Le Reti Neurali sono essenzialmente dei modelli di calcolo matematico che si basano sul funzionamento delle Reti Neurali Biologiche. Quindi sistemi che mettono in relazione set di informazioni diverse, proprio come avviene nel nostro cervello nella comunicazione tra i neuroni. In questo ambito vengono solitamente applicati modelli di calcolo distribuito in parallelo, proprio per cercare di riprodurre quello che avviene nella nostra mente durante un ragionamento.
Il Deep Learning è correlato al concetto di reti neurali, ma basato su più livelli di rappresentazione, o meglio gerarchie, dove ogni livello applica tecniche basate su Reti Neurali per analizzare i dati e generare quindi l’output per il livello successivo, elaborando di volta in volta le informazioni in maniera sempre più approfondita man mano che si avanza di livello.
Applicazioni pratiche di questo ambito possono essere ad esempio le analisi delle sequenze di geni o i processi biochimici che avvengono nelle cellule.
IL FUTURO DEL MACHINE LEARNING
Gli argomenti relativi al ML sono talmente numerosi e vasti che questo vuole essere un semplice articolo introduttivo, ma di sicuro la strada da fare è ancora molta. Sebbene i concetti di ML siano nati agli albori dell’informatica, solo recentemente hanno acquisito molta notorietà per via del sempre più alto utilizzo di robot e di sistemi autonomi che sono entrati a far parte della normalità della nostra vita.
Un sondaggio del Future of Humanity Institute afferma:
“i ricercatori credono che ci sia il 50% di possibilità che le macchine, tramite l’Intelligenza Artificiale, superino gli umani nello svolgimento di qualsiasi attività nel giro di 45 anni”.
Ad essere corretti, questo tipo di affermazione è stato fatto più volte anche in passato e ci ritroviamo ancora ai livelli di oggi, dove il margine di miglioramento è sicuramente molto ampio, ma è innegabile che l’interesse che sta acquisendo l’argomento ML stia diventando sempre più forte visti i numerosi campi di applicazione.
Quello di cui siamo sicuri è che verranno fatti grossi investimenti in questo settore e che avremo notevoli miglioramenti nei prossimi anni in questo campo di ricerca.
Leggi la prima parte dell’articolo: Machine Learning: come le macchine apprendono – PARTE 1
